News summary: New libraries in accelerated computing deliver order-of-magnitude speedups and reduce energy consumption and costs in data processing, generative AI, recommender systems, AI data curation, data processing, 6G research, AI-physics and more. They include:
- LLM applications: NeMo Curator, to create custom datasets, adds image curation and Nemotron-4 340B for high-quality synthetic data generation
- Data processing: cuVS for vector search to build indexes in minutes instead of days and a new Polars GPU Engine in open beta
- Physical AI: For physics simulation, Warp accelerates computations with a new TIle API. For wireless network simulation, Aerial adds more map formats for ray tracing and simulation. And for link-level wireless simulation, Sionna adds a new toolchain for real-time inference
Companies around the world are increasingly turning to NVIDIA accelerated computing to speed up applications they first ran on CPUs only. This has enabled them to achieve extreme speedups and benefit from incredible energy savings.
In Houston, CPFD makes computational fluid dynamics simulation software for industrial applications, like its Barracuda Virtual Reactor software that helps design next-generation recycling facilities. Plastic recycling facilities run CPFD software in cloud instances powered by NVIDIA accelerated computing. With a CUDA GPU-accelerated virtual machine, they can efficiently scale and run simulations 400x faster and 140x more energy efficiently than using a CPU-based workstation.

A popular video conferencing application captions several hundred thousand virtual meetings an hour. When using CPUs to create live captions, the app could query a transformer-powered speech recognition AI model three times a second. After migrating to GPUs in the cloud, the application’s throughput increased to 200 queries per second — a 66x speedup and 25x energy-efficiency improvement.
In homes across the globe, an e-commerce website connects hundreds of millions of shoppers a day to the products they need using an advanced recommendation system powered by a deep learning model, running on its NVIDIA accelerated cloud computing system. After switching from CPUs to GPUs in the cloud, it achieved significantly lower latency with a 33x speedup and nearly 12x energy-efficiency improvement.
With the exponential growth of data, accelerated computing in the cloud is set to enable even more innovative use cases.
NVIDIA Accelerated Computing on CUDA GPUs Is Sustainable Computing
NVIDIA estimates that if all AI, HPC and data analytics workloads that are still running on CPU servers were CUDA GPU-accelerated, data centers would save 40 terawatt-hours of energy annually. That’s the equivalent energy consumption of 5 million U.S. homes per year.
Accelerated computing uses the parallel processing capabilities of CUDA GPUs to complete jobs orders of magnitude faster than CPUs, improving productivity while dramatically reducing cost and energy consumption.
Although adding GPUs to a CPU-only server increases peak power, GPU acceleration finishes tasks quickly and then enters a low-power state. The total energy consumed with GPU-accelerated computing is significantly lower than with general-purpose CPUs, while yielding superior performance.

In the past decade, NVIDIA AI computing has achieved approximately 100,000x more energy efficiency when processing large language models. To put that into perspective, if the efficiency of cars improved as much as NVIDIA has advanced the efficiency of AI on its accelerated computing platform, they’d get 500,000 miles per gallon. That’s enough to drive to the moon, and back, on less than a gallon of gasoline.
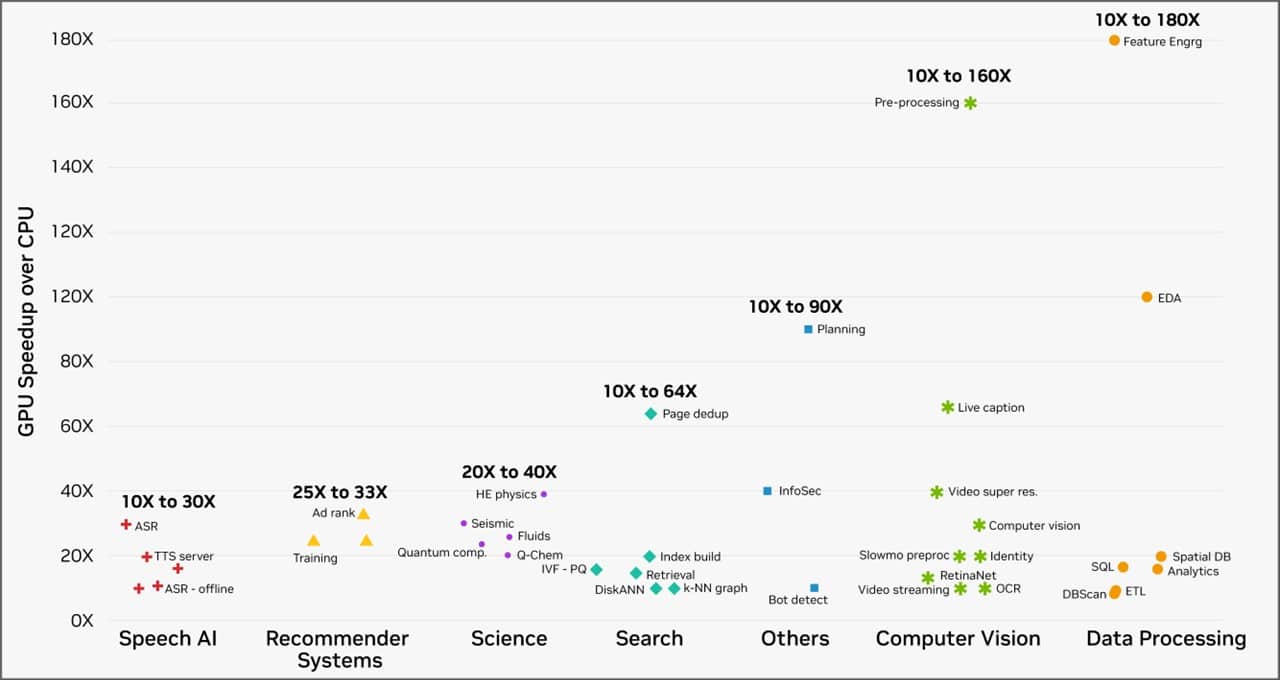
In addition to these dramatic boosts in efficiency on AI workloads, GPU computing can achieve incredible speedups over CPUs. Customers of the NVIDIA accelerated computing platform running workloads on cloud service providers saw speedups of 10-180x across a gamut of real-world tasks, from data processing to computer vision, as the chart below shows.

As workloads continue to demand exponentially more computing power, CPUs have struggled to provide the necessary performance, creating a growing performance gap and driving “compute inflation.” The chart below illustrates a multiyear trend of how data growth has far outpaced the growth in compute performance per watt of CPUs.

The energy savings of GPU acceleration frees up what would otherwise have been wasted cost and energy.
With its massive energy-efficiency savings, accelerated computing is sustainable computing.
The Right Tools for Every Job
GPUs cannot accelerate software written for general-purpose CPUs. Specialized algorithm software libraries are needed to accelerate specific workloads. Just like a mechanic would have an entire toolbox from a screwdriver to a wrench for different tasks, NVIDIA provides a diverse set of libraries to perform low-level functions like parsing and executing calculations on data.
Each NVIDIA CUDA library is optimized to harness hardware features specific to NVIDIA GPUs. Combined, they encompass the power of the NVIDIA platform.
New updates continue to be added on the CUDA platform roadmap, expanding across diverse use cases:
LLM Applications
NeMo Curator gives developers the flexibility to quickly create custom datasets in large language model (LLM) use cases. Recently, we announced capabilities beyond text to expand to multimodal support, including image curation.
SDG (synthetic data generation) augments existing datasets with high-quality, synthetically generated data to customize and fine-tune models and LLM applications. We announced Nemotron-4 340B, a new suite of models specifically built for SDG that enables businesses and developers to use model outputs and build custom models.
Data Processing Applications
cuVS is an open-source library for GPU-accelerated vector search and clustering that delivers incredible speed and efficiency across LLMs and semantic search. The latest cuVS allows large indexes to be built in minutes instead of hours or even days, and searches them at scale.
Polars is an open-source library that makes use of query optimizations and other techniques to process hundreds of millions of rows of data efficiently on a single machine. A new Polars GPU engine powered by NVIDIA’s cuDF library will be available in open beta. It delivers up to a 10x performance boost compared to CPU, bringing the energy savings of accelerated computing to data practitioners and their applications.
Physical AI
Warp, for high-performance GPU simulation and graphics, helps accelerate spatial computing by making it easier to write differentiable programs for physics simulation, perception, robotics and geometry processing. The next release will have support for a new Tile API that allows developers to use Tensor Cores inside GPUs for matrix and Fourier computations.
Aerial is a suite of accelerated computing platforms that includes Aerial CUDA-Accelerated RAN and Aerial Omniverse Digital Twin for designing, simulating and operating wireless networks for commercial applications and industry research. The next release will include a new expansion of Aerial with more map formats for ray tracing and simulations with higher accuracy.
Sionna is a GPU-accelerated open-source library for link-level simulations of wireless and optical communication systems. With GPUs, Sionna achieves orders-of-magnitude faster simulation, enabling interactive exploration of these systems and paving the way for next-generation physical layer research. The next release will include the entire toolchain required to design, train and evaluate neural network-based receivers, including support for real-time inference of such neural receivers using NVIDIA TensorRT.
NVIDIA provides over 400 libraries. Some, like CV-CUDA, excel at pre- and post-processing of computer vision tasks common in user-generated video, recommender systems, mapping and video conferencing. Others, like cuDF, accelerate data frames and tables central to SQL databases and pandas in data science.

Many of these libraries are versatile — for example, cuBLAS for linear algebra acceleration — and can be used across multiple workloads, while others are highly specialized to focus on a specific use case, like cuLitho for silicon computational lithography.
For researchers who don’t want to build their own pipelines with NVIDIA CUDA-X libraries, NVIDIA NIM provides a streamlined path to production deployment by packaging multiple libraries and AI models into optimized containers. The containerized microservices deliver improved throughput out of the box.
Augmenting these libraries’ performance are an expanding number of hardware-based acceleration features that deliver speedups with the highest energy efficiencies. The NVIDIA Blackwell platform, for example, includes a decompression engine that unpacks compressed data files inline up to 18x faster than CPUs. This dramatically accelerates data processing applications that need to frequently access compressed files in storage like SQL, Apache Spark and pandas, and decompress them for runtime computation.
The integration of NVIDIA’s specialized CUDA GPU-accelerated libraries into cloud computing platforms delivers remarkable speed and energy efficiency across a wide range of workloads. This combination drives significant cost savings for businesses and plays a crucial role in advancing sustainable computing, helping billions of users relying on cloud-based workloads to benefit from a more sustainable and cost-effective digital ecosystem.
Learn more about NVIDIA’s sustainable computing efforts and check out the Energy Efficiency Calculator to discover potential energy and emissions savings.
See notice regarding software product information.
Blog Article: Here